If you are working with high volumes of data and you need a way to eliminate duplicates stemming from various data sources, an automated deduplication process can potentially save you and your team valuable time and effort and prevent errors.
Duplicates can appear in contacts, company or deal details in a CRM, ERP or database, or in contact lists for marketing and sales, with data coming from both structured as well as unstructured sources such as online forms or surveys.
In marketing, duplicates can cause bad leads data and hurt brand reputation. In sales, duplicates can harm customer relationships as sales representatives could engage with leads or prospects but miss information and context.
Setting up a deduplication process can help you filter, categorize, merge and clean data, and also optimize your processes to prevent duplicates from being created in the future.
You can either use a built-in deduplication process that is integrated with your data sources and automatically identifies duplicates in real-time, or you can manually import lists from data sources such as spreadsheets, Access, SQL servers or other sources and run deduplication processes manually.
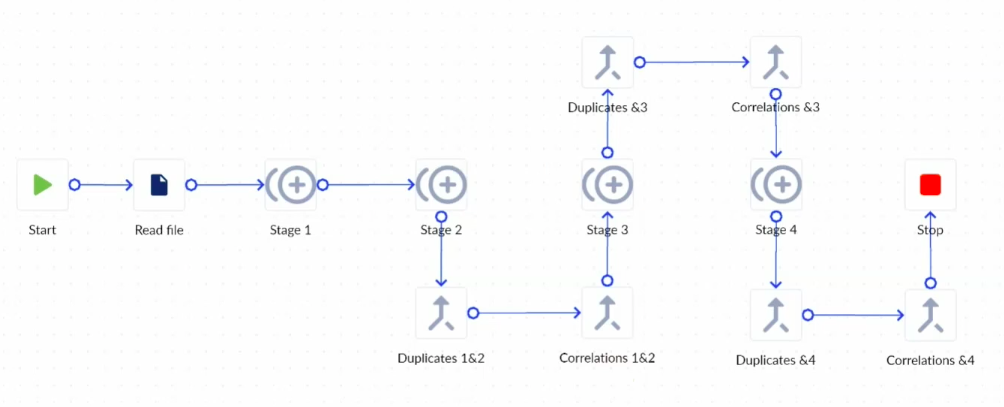
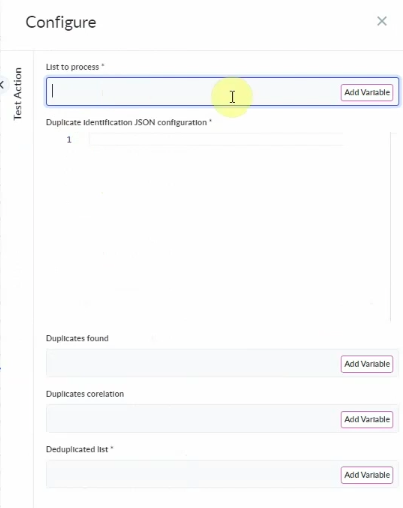
In the deduplication process I have built in PROCESIO below, I am using a special Custom Action called ‘Deduplicate Identification’ which helps me to customize the deduplication process to my own requirements.
My source of data is a spreadsheet which I am plugging in the process using a Get File Data action. I have set up four stages in total so that I can identify duplicates by different criteria, and the outputs include the duplicates as well as a contextual correlation between the duplicate records and master records so that I can identify and merge them if necessary.